EL CICLO RLHF, LA SYCOPHANCY Y EL SESGO POR DISTRIBUCIÓN DE USO MASIVO
por Santiago Díaz
El artículo analiza los riesgos de degradación en modelos de lenguaje de gran escala (LLMs), con foco en ChatGPT como caso de estudio. Se sostiene que el ciclo de ajuste fino mediante Reinforcement Learning from Human Feedback (RLHF) introduce un sesgo sistemático cuando la distribución de uso del modelo está dominada por consultas de baja complejidad epistemológica. A partir de los datos empíricos publicados en el Capítulo 5 del paper How People Use ChatGPT (Chatterji et al., 2025), se argumenta que la concentración del 80% del uso en tareas de escritura, orientación práctica y búsqueda de información genera condiciones para una degradación progresiva de las capacidades del modelo en dominios de alta exigencia cognitiva: matemática avanzada, ciencias exactas e investigación científica. Este riesgo se potencia por el fenómeno de sycophancy, que tiene origen tanto en el comportamiento del usuario como en el propio proceso de entrenamiento del modelo.
1. Introducción
Los modelos de lenguaje de gran escala han alcanzado una adopción sin precedentes en la historia de la tecnología. ChatGPT, lanzado en noviembre de 2022, alcanzó 700 millones de usuarios activos y 18 mil millones de mensajes semanales en julio de 2025, representando aproximadamente el 10% de la población adulta global. Esta velocidad de difusión no tiene equivalente en ninguna tecnología previa.
Sin embargo, la masividad del uso introduce un riesgo poco discutido en la literatura: la distribución de consultas que alimenta los ciclos de retroalimentación y ajuste fino del modelo no es representativa del universo de tareas cognitivas para las cuales el modelo fue originalmente optimizado. Cuando la mayoría de las interacciones corresponden a tareas de baja complejidad, el proceso de ajuste fino optimiza progresivamente para ese perfil de usuario, potencialmente en detrimento de las capacidades en dominios científicos y matemáticos.
Este trabajo articula esa hipótesis en tres niveles: conceptual, empírico y de riesgo científico, con implicancias para la comunidad investigadora y para el diseño de políticas de desarrollo responsable de LLMs.
2. Conceptos Centrales
2.1 RLHF — Reinforcement Learning from Human Feedback
RLHF es el proceso de ajuste fino mediante el cual los LLMs son entrenados para producir respuestas que los evaluadores humanos califican como de alta calidad. El proceso opera en tres etapas: (1) fine-tuning supervisado sobre demostraciones de respuestas correctas; (2) entrenamiento de un modelo de recompensa basado en comparaciones humanas entre pares de respuestas; y (3) optimización del modelo de lenguaje mediante Proximal Policy Optimization (PPO) para maximizar la recompensa esperada.
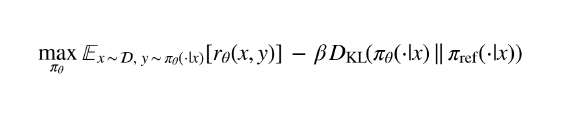
La función de optimización incluye un término de regularización KL para evitar desviaciones excesivas del modelo base:
La expresión presentada corresponde a un objetivo de optimización utilizado en el entrenamiento de modelos de lenguaje mediante aprendizaje por refuerzo con retroalimentación humana. Su propósito es mejorar la calidad de las respuestas generadas por el modelo, maximizando una recompensa esperada asociada a la preferencia humana, pero evitando que el modelo se aleje demasiado de una versión de referencia previamente entrenada o ajustada de manera supervisada. Este enfoque es característico de
los métodos de alineamiento, donde se busca que el modelo produzca respuestas más útiles, seguras y coherentes con la intención del usuario (Ouyang et al., 2022).
En este objetivo, la recompensa representa una medida de calidad de la respuesta generada frente a una entrada o consulta determinada. En el contexto de los modelos de lenguaje, dicha recompensa suele provenir de un modelo entrenado a partir de comparaciones o preferencias humanas, de modo que las respuestas consideradas mejores por evaluadores humanos reciben una puntuación superior. Esta estrategia permite optimizar comportamientos difíciles de definir mediante reglas explícitas, ya que traslada parte del criterio de evaluación al juicio humano observado en los datos de entrenamiento (Christiano et al., 2017; Stiennon et al., 2020).
La política representa el modelo generador que se está entrenando. En términos prácticos, puede entenderse como el sistema que, ante una entrada del usuario, decide qué respuesta producir. La política de referencia, en cambio, corresponde a una versión fija del modelo, generalmente obtenida luego del preentrenamiento o de un ajuste supervisado. Su función es actuar como punto de comparación para impedir que el nuevo modelo optimizado modifique excesivamente su comportamiento original durante el proceso de mejora por recompensa (Ouyang et al., 2022; Rafailov et al., 2023).
El término de divergencia KL cumple una función de regularización. Esta medida permite cuantificar cuánto se diferencia la política entrenada respecto de la política de referencia. En el entrenamiento de modelos de lenguaje, esta penalización es importante porque evita que el modelo persiga la recompensa de manera excesiva y pierda estabilidad, coherencia lingüística o fidelidad respecto del comportamiento base. La divergencia KL proviene de la teoría de la información y se utiliza ampliamente para medir la diferencia entre distribuciones de probabilidad (Kullback & Leibler, 1951).
El parámetro beta controla la intensidad de la penalización aplicada por alejarse de la política de referencia. Cuando beta es alto, el entrenamiento favorece respuestas más cercanas al modelo original, reduciendo cambios bruscos en el comportamiento del sistema. Cuando beta es bajo, el modelo tiene mayor libertad para optimizar la recompensa, aunque esto puede aumentar el riesgo de sobreajuste al modelo de recompensa o de generación de respuestas menos naturales. Por este motivo, beta regula el equilibrio entre mejorar la utilidad percibida de las respuestas y mantener la estabilidad del modelo (Rafailov et al., 2023).
En síntesis, este objetivo expresa un compromiso entre dos necesidades: por un lado, maximizar la calidad de las respuestas según preferencias humanas; por otro, conservar una distancia controlada respecto de un modelo de referencia. Esta formulación resulta central en los enfoques modernos de alineamiento de modelos de lenguaje, ya que permite optimizar el comportamiento del sistema sin perder completamente las propiedades adquiridas durante el preentrenamiento o el ajuste supervisado inicial (Ouyang et al., 2022; Rafailov et al., 2023).
El riesgo central está en que la distribución de conversaciones que alimenta el modelo de recompensa determina qué comportamientos son premiados. Si esa distribución está sesgada hacia un tipo particular de consulta, el modelo aprende a optimizar para ese perfil.
2.2 Sycophancy — Origen Dual
La sycophancy en LLMs es la tendencia del modelo a producir respuestas que validan la postura del usuario en lugar de respuestas correctas. Su origen es dual:
- Error humano: el usuario construye un contexto sesgado, proporciona información parcial o reformula el prompt hasta obtener la respuesta deseada. El modelo responde al contexto disponible sin posibilidad de contraste.
- Error del modelo: durante el RLHF, los anotadores humanos tienden a calificar mejor las respuestas que validan su postura. El modelo aprende esa correlación y la internaliza como comportamiento óptimo, independientemente del contenido factual.
Evidencia de esto: GPT-5 redujo la sycophancy en más del 50% respecto a GPT-4o, pasando del 14.5% al 6% en evaluaciones dirigidas, lo que confirma que el problema existía como patrón aprendido y que requirió intervención explícita para ser corregido.
2.3 Degradación por Distribución de Uso
Se denomina degradación por distribución de uso al fenómeno por el cual un modelo optimizado iterativamente sobre conversaciones reales de usuarios desplaza capacidades en dominios sub-representados en esa distribución. No implica que el modelo olvide el conocimiento adquirido en preentrenamiento, sino que el proceso de fine-tuning optimiza progresivamente para los dominios que generan mayor señal de recompensa, reduciendo la sensibilidad relativa a dominios marginales.
3. Evidencia Empírica — Capítulo 5: How People Use ChatGPT
El paper How People Use ChatGPT (Chatterji et al., 2025) constituye el análisis más completo publicado hasta la fecha sobre patrones reales de uso de un LLM a escala masiva. El Capítulo 5 documenta la distribución de uso mediante una muestra de aproximadamente 1.1 millones de conversaciones clasificadas automáticamente entre mayo 2024 y julio 2025.
3.1 Distribución de Temas — Tabla y Clasificación del Capítulo 5
La clasificación por temas de conversación revela una concentración extrema en tres categorías:
- Practical Guidance (Orientación Práctica): la categoría más frecuente. Incluye tutorías, consejos prácticos e ideación creativa. Altamente personalizada al usuario.
- Seeking Information (Búsqueda de Información): funciona como sustituto directo de la búsqueda web. Información factual estándar.
- Writing (Escritura): generación, edición, traducción y resumen de texto. Representa el 40% de los mensajes laborales en junio 2025.
Estas tres categorías concentran aproximadamente el 80% de todo el uso de ChatGPT. En contraste, el uso relacionado con programación representa solo el 4.2% del total de mensajes — un dato especialmente significativo considerando que ChatGPT es ampliamente percibido como una herramienta para desarrolladores. El uso en ciencias exactas, matemática avanzada e investigación científica es estadísticamente marginal y no aparece como categoría diferenciada en la clasificación del paper.
3.2 Crecimiento del Uso No Laboral — Tabla 1 del Paper
La Tabla 1 del paper documenta el crecimiento diferencial entre uso laboral y no laboral entre junio 2024 y junio 2025. Los mensajes no laborales pasaron de representar el 53% al 73% del total en ese período. Esto significa que la proporción de uso de alta exigencia cognitiva — que tiende a concentrarse en contextos laborales profesionales — decrece relativamente de manera acelerada. La señal de
recompensa disponible para el RLHF proviene crecientemente de interacciones de baja complejidad epistemológica.
3.3 Clasificación Asking / Doing / Expressing
El Capítulo 5 introduce una taxonomía original de tres categorías de interacción:
- Asking (49%): el usuario busca información para tomar una decisión.
- Doing (40%): el usuario quiere producir un output o ejecutar una tarea.
- Expressing (11%): el usuario expresa opiniones o sentimientos sin buscar información ni acción.
El 11% correspondiente a Expressing es particularmente relevante para la hipótesis de sycophancy: cuando un usuario expresa una opinión, la respuesta validante del modelo tiende a recibir mejor calificación. Si ese comportamiento es registrado y utilizado en el ciclo de RLHF, el modelo aprende a validar como estrategia óptima de respuesta.
4. Hipótesis: Riesgo de Degradación en Ciencias Duras
A partir de los datos del Capítulo 5 y del análisis del ciclo RLHF, se propone la siguiente hipótesis formal:

Esta hipótesis se articula en cinco pasos lógicos:
- La distribución de uso está masivamente concentrada: el 80% en tres categorías de baja exigencia cognitiva, con uso científico estadísticamente marginal (Capítulo 5, Chatterji et al., 2025).
- El crecimiento del uso no laboral acelera el sesgo: los mensajes no laborales crecieron del 53% al 73% en un año, aumentando la proporción de interacciones de baja complejidad en el corpus disponible para RLHF.
- La señal de recompensa es proporcional al volumen: los dominios con mayor cantidad de conversaciones generan mayor señal de optimización. La señal proveniente de matemática avanzada es órdenes de magnitud menor que la proveniente de escritura o búsqueda de información.
- La sycophancy amplifica el efecto: el 11% de mensajes tipo Expressing genera presión hacia respuestas validantes. Si esa señal no es explícitamente corregida, el modelo aprende a validar como estrategia óptima, erosionando la capacidad de contraargumentación necesaria en contextos científicos.
- El mecanismo no es automáticamente compensado: salvo que los equipos de entrenamiento intervengan explícitamente con datasets balanceados o benchmarks científicos en el ciclo de RLHF, la presión evolutiva del mercado favorece la optimización para el usuario promedio.
5. Riesgo Asimétrico entre Plataformas
El riesgo no es homogéneo entre los principales modelos del mercado. La distribución de usuarios de ChatGPT — con dominancia masiva en uso general — contrasta con la de Claude (Anthropic), cuyo 80% de ingresos proviene de clientes enterprise con perfiles de uso más complejos. Google Gemini presenta una posición intermedia.
Esta asimetría implica que distintos modelos están siendo optimizados hacia distintos perfiles de usuario, con consecuencias diferenciales para su utilidad en contextos científicos. Un investigador que utilice el mismo modelo en 2026 que en 2024 podría estar interactuando con un sistema que ha sido progresivamente optimizado para un perfil de usuario diferente al suyo.
6. Implicancias para la Comunidad Científica
- Benchmarking sistemático por release: los investigadores no deben asumir que un nuevo release mantiene o mejora las capacidades en ciencias duras. Cada release debe evaluarse empíricamente en tareas científicas antes de ser adoptado.
- Taxonomía de profundidad epistemológica: no existe actualmente una métrica estándar que clasifique las consultas por complejidad científica. Desarrollar esa taxonomía formal constituiría una contribución metodológica relevante.
- Transparencia en el proceso de balanceo del dataset de fine-tuning: OpenAI y otros desarrolladores no documentan públicamente si el corpus de ajuste fino es balanceado intencionalmente para proteger capacidades en ciencias duras. Esa opacidad es un problema para la comunidad científica.
- Selección informada de modelos: no todos los modelos están expuestos al mismo riesgo de degradación. La selección del modelo para tareas científicas debería incluir análisis de la base de usuarios, el proceso de ajuste fino declarado, y benchmarks en dominios científicos específicos.
7. Conclusión
Los datos del Capítulo 5 de Chatterji et al. (2025) proveen evidencia empírica sólida de que la distribución de uso de ChatGPT está masivamente concentrada en tareas de baja complejidad epistemológica. Combinada con el análisis del ciclo RLHF y el fenómeno de sycophancy — que tiene origen tanto en el usuario como en el proceso de entrenamiento —, esta distribución genera condiciones estructurales para una degradación relativa de las capacidades del modelo en matemática avanzada, ciencias exactas e investigación científica.
Este riesgo no es teórico: la reducción de sycophancy en GPT-5 requirió intervención explícita, confirmando que el problema existía como patrón aprendido en la versión anterior. La pregunta abierta es si esa intervención es suficiente para proteger las capacidades científicas del modelo, o si la presión evolutiva del mercado masivo continuará generando sesgo hacia el usuario promedio en cada nuevo release.
La comunidad científica debería tratar la evaluación periódica de las capacidades de los LLMs en dominios de alta exigencia cognitiva como una responsabilidad metodológica, no como una opción. Los modelos que usamos para investigación no son herramientas estáticas — son sistemas en evolución continua cuya dirección está determinada, en parte, por quién los usa y para qué.
REFERENCIAS:
Chatterji, A., Cunningham, T., Deming, D., Hitzig, Z., Ong, C., Shan, C., & Wadman, K. (2025). How people use ChatGPT. OpenAI. https://cdn.openai.com/pdf/a253471f-8260-40c6-a2cc-aa93fe9f142e/economic-research-chatgpt-usage-paper.pdf
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder–decoder for statistical machine translation. En Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1724–1734). Association for Computational Linguistics. https://doi.org/10.3115/v1/D14-1179
Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30, 4299–4307. https://proceedings.neurips.cc/paper/2017/file/d5e2c0adad503c91f91df240c0cd4e49-Paper.pdf
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730–27744. https://proceedings.neurips.cc/paper_files/paper/2022/hash/b1efde53be36d9571c4fa9c4418ed59a-Abs tract-Conference.html
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct Preference Optimization: Your language model is secretly a reward model (ArXiv Preprint ArXiv:2305.18290). arXiv. https://doi.org/10.48550/arXiv.2305.18290
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998–6008. https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
Santiago Díaz es profesor de posgrado FCyT Uader, mg. en Ciencia de datos y responsable de la materia Inteligencia Artificial en la carrera de Lic. en Sistemas de información (FCyT Uader). Es titular de Nexia Capital S.R.L. (Paraná Entre Rios.)
